I’m very pro “just running the code” when it comes to testing software. But while just spinning up containers does actually “work” – in the sense that the test runs and completes without error. But you very quickly realize that’s clearly not how these things are supposed to work. I’ve been using testcontainers to test the gift registry app I’ve been working on, and it’s been great. I’ve implemented a basic passwordless login setup, and I can test every part of this using live code with the sole exception of actually sending an email via a simple make test. But this was very obviously not the best way to go about it, as you can see from the test output:
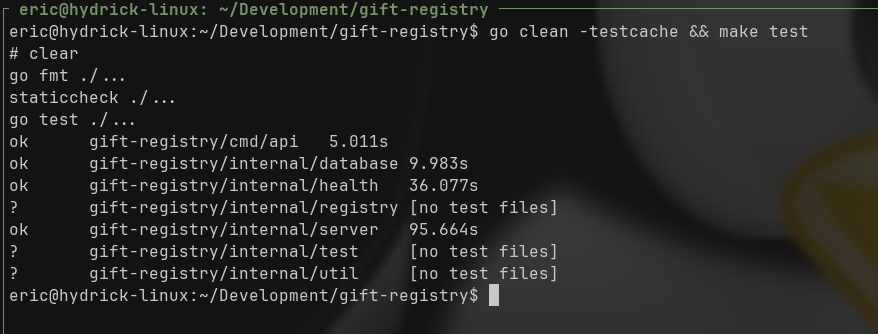
Sure…the tests are finishing successfully, but 96 seconds? Over a minute and a half to test just a login page? That’s f***ing terrible. And I’m running the tests in parallel, this is absolutely unacceptable. So I stopped and did some refactoring on my test approach. I still want my test command to run a local copy of the server, but this should be running in a handful of seconds at most.
Playwright is a bit much
This app is a fairly simple stack – basically Go for the server and HTMX and Go’s built-in templating library for the UI. I’ve written a health check endpoint, a passwordless login page that emails a random token if the email address matches a user record, and a simple authentication middleware. I’m not writing particularly complicated pages, and unit testing the output basically involves confirming expected elements are either visible on the page, or hidden from view. I had been using Playwright to confirm the page loaded and that the elements were appearing or hidden as expected.
I was excited to be using the framework at first because I could confirm my page worked as expected on a variety of headless browsers, but Playwright accounted for several seconds in each test case. Go has an HTML parser, but Playwright was just easier to use for finding elements and checking visibility. It wasn’t multiple seconds per test case easier though, so I went back to the first couple of tests I wrote using the native Go HTML parser, and built a function that did a depth-first search for a given element. If I commit to controlling whether or not an element is displayed by using either the hidden property or class, then using that depth-first search function could be extended to check for the element being visible . For the record, I’m sure Playwright’s checks are more thorough and cover all the browser engines, but that’s the type of thing that can wait and run when I’m building a release candidate Docker image, not running a local unit test to sanity-check my work as I’m coding.
Quick startup times are still startup times
Pulling Playwright helped, (I saved 10-20 seconds per test run), but I still wasn’t seeing these tests run nearly as fast as I would expect. Doing a little during some test runs confirmed that launching testing containers for each test case was slowing me down by a lot more than I thought.
There were 2 problems with how I was using testcontainers. The most blatant came from testing my health check endpoint, of all things. Part of my goal was to get some practice setting up telemetry and writing that to an OpenTelemetry back-end. To that end, I’ve been using the Grafana LGTM stack, specifically their all-in-one image (because even in “production,” I’m not going to have a lot of users. It has a handy testcontainers module – that would take about 30 seconds to come up. That just will not do.
I was spinning up an observability container because I was pinging it as part of my health check endpoint, essentially just checking to confirm that I could send out telemetry data. I had the container included in my docker-compose file, so I justified it as making sure my app was properly connected to a piece of my stack. I was pinging the database, why not ping telemetry? Because testing that endpoint left me sitting around waiting for too long, that’s why (also because if I build another project, and I’d like to, and send out telemetry from that, then my telemetry stack would need to be a stand-alone piece).
Dropping that was easy. But there was another issue with my use of testcontainers – the database containers. On the surface this didn’t seem as bad – it spun up in a couple of seconds. But I was creating a new instance per each test case – so that’s a couple of seconds for every scenario I wanted to test. So a startup time that’s acceptable on its own was own was ballooning into tons of time wasted. Nope, that won’t do at all either.
The updated testing setup
As a quick primer if you haven’t tried out Go, I’m doing table-driven testing, where basically I have a test function that declares a slice1 of structs that has the details for each test case. Then I just iterate over the list of test details and run each test case in parallel.
Given this setup, my first thought, having been thoroughly indoctrinated that each test case must run in a pristine environment, was to just set up the database outer function, before I start my test loop, and close it after the loop. That would keep the tests as close to “fresh” as possible, but still let me reuse these containers. Except for the part where the actual test cases started executing and failing because the database connection was already closed.
My first thought was that Go treats tests being run with the t.Parallel() command as a goroutine under the hood, but was confused why it wasn’t bound to a WaitGroup at said test level. My best guess was that any WaitGroup would have been set on the TestMain(m *testing.M) function, since surely there’s a wait happening somewhere, and TestMain was the only viable suspect if the parallel execution wasn’t bound to the tests. Nevertheless, I got my containers re-used (more on that in a bit), and carried on, with a plan to look up how t.Parallel() works later. Now that it’s later, I realized what was going on under the hood thanks to this article, specifically, this line:
If a subtest function using
t.Run()calls thet.Parallel()method, the subtest function will pause once thet.Parallel()method is called, and remain paused until its parent top-level test function completes and returns.
So…not weird goroutine behavior, but OK. On to database reuse! If I couldn’t create the database at the test level, I’d just create it at the package level, in the TestMain(m *testing.M)method. This gave me 1 database container for the package, but 2 seconds per package to start up a database is much more manageable (PS – if anyone knows how to run a function before any test executes, I’d love to start the database container there). This absolutely sped things up, although I had to start taking care not to re-use things like user records in multiple tests. That wasn’t hard by any stretch of the imagination, just ensuring that accounts I created used test case-specific email addresses.
How’d this work out for me? Much better:
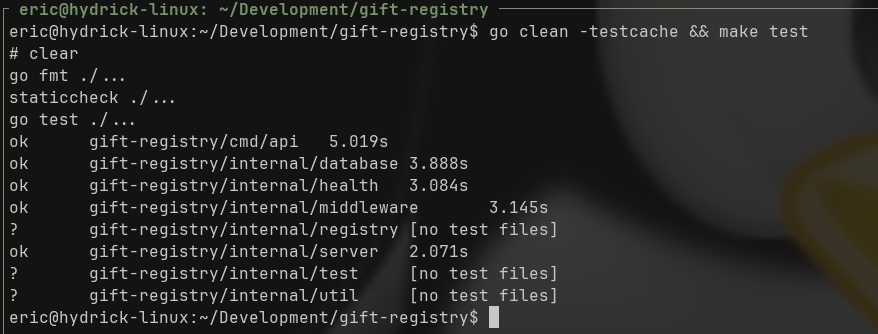
My main package is still slow because I’m testing a graceful shutdown method that gives the application 5 seconds to wrap up whatever it’s doing. For everything else, tests are 2-3 seconds, which isn’t bad considering for each package there’s a 2ish-second startup time to get a database up and going.
Other lessons learned
Being pushed into putting my database container into the package’s TestMain(m *testing.M) function was probably the best thing to happen to the tests. Not just because of the performance improvements (although they were massive), but because it led me to start putting more of the repeated test setup code in there instead of each test. Now my test setups look something like this:
// TestMain sets up the application tests by initializing a logger object to
// use in the methods and initializing a context.
func TestMain(m *testing.M) {
ctx = context.Background()
/* Sets up a testing logger */
options := &slog.HandlerOptions{Level: slog.LevelDebug, AddSource: true}
handler := slog.NewTextHandler(os.Stderr, options)
logger = slog.New(handler)
dbPath = filepath.Join("..", "..", "docker", "postgres_scripts", "init.sql")
dbCont, dbURL, err := test.BuildDBContainer(ctx, dbPath, dbName, dbUser, dbPass)
defer func() {
if err := testcontainers.TerminateContainer(dbCont); err != nil {
log.Fatal("Failed to terminate the database test container ", err)
}
}()
if err != nil {
log.Fatal("Error setting up a test database", err)
}
env := map[string]string{
"DB_HOST": strings.Split(dbURL, ":")[0],
"DB_USER": dbUser,
"DB_PASS": dbPass,
"DB_PORT": strings.Split(dbURL, ":")[1],
"DB_NAME": dbName,
"MIGRATIONS_DIR": filepath.Join("..", "..", "internal", "database", "migrations"),
"STATIC_FILES_DIR": filepath.Join("..", "..", "cmd", "web"),
"TEMPLATES_DIR": filepath.Join("..", "..", "cmd", "web", "templates"),
}
getenv = func(name string) string { return env[name] }
db, err = database.Connection(ctx, logger, getenv)
if err != nil {
log.Fatal("database connection failure! ", err)
}
/* This is the 1 thing I need to mock in my tests */
emailer = &test.EmailMock{
EmailToToken: map[string]string{},
EmailToSent: map[string]bool{},
}
appHandler, err := server.NewServer(getenv, db, logger, emailer)
if err != nil {
log.Fatal("Error setting up the test handler", err)
}
testServer = httptest.NewServer(appHandler)
defer testServer.Close()
exitCode := m.Run()
os.Exit(exitCode)
}
That not only cleaned up my tests, but made it so that running said tests looked a lot more like running my application. I had 1 instance of my server, 1 instance of my database, and a bunch of operations happening against those singletons. In other words, now we’re codin’ dirty.
Thanks to this test refactoring (and thus running tests repeatedly and often), I learned that different application configurations should require different test functions. Most of my configuration is done via environment variables, which are actually accessed via a getenv function (an idea I got from here). When the application is running, getenv is nothing more than a wrapper around os.Getenv but for testing, I can just build a custom map of strings (environment variable names) to strings (values). Now I can overwrite my environment settings based on what I’m testing.
The key here is that different sets of environment variables should go into their own test method. I tried just updating them before calling functions in my application, but the test refactoring exposed some concurrency issues with that approach. Since a “real” run of the application won’t have different callers interacting with different sets of environment variables, the tests shouldn’t do it either.
Just running the code is a viable testing strategy, but you can’t do it like unit test, where each test case is it’s own fresh application instance. Well…you can…but it’s going to be painfully slow. Instead, you need to commit to running your tests like you application, re-using your database and application server as much as possible. “But…what about tests creating side effects that interfere with other tests?” – that’s going to be an issue when you run your app anyways, so you might as well make it as easy as possible to expose that kind of bug during a make test instead of waiting till it’s on a live server somewhere causing problems for someone else.
There’s a couple of more development cycle speedups and enhancements I want to make. I moved my telemetry from going straight to the observability back-end to exporting to a collector. The plan here is to break the observability back-end out of my docker-compose and make it something that can be optionally included. But I’m curious if spinning up the collector container is fast enough that I can connect to it back in my health check.
The other is speeding up refreshes of code when developing. Right now I’m doing a simple docker compose up -d on my stack to run the application, which is fast enough…except for my application Dockerfile that builds the app each time. That’s about 30-40 seconds per run. In theory it’s possible to mount the application directory and just go run cmd/api/main.go, but I haven’t gotten that work for me yet. The other options are spinning up the database, telemetry collector and back-end as containers, and just calling go run cmd/api/main.go from my local terminal, or using a tool like Air. Either way, I’d like faster reloads for development, although the unit tests work well enough that most of what I need to cycle on are things like page layout and styling.
All in all, after a (much longer than anticipated) detour into setting up a passwordless login page, feel like I’m finally ready to start working on the application part of this exercise, thanks in part to tests that actually provide me with quick feedback.
- Slices are similar to arrays in other languages, it’s just that in Go an array’s length is part of the type (e.g. [3]int represents a different array “type” than [4]int). Slices aren’t so restrictive, so they generally get used instead ↩︎